你有沒有用過 Python 、 Multicharts、R 等等的回測工具嗎?
工具越來越強大,伴隨著平行運算,參數最佳化變得越來越容易
但有時候,這些強大的工具,反而是一種陷阱!
讓我們一步步走進陷阱而不自知
就連學術期刊都如此!
一個策略可能有很多的參數,可以用來進行最佳化
你會發現,當參數越多,越有可能會找到很好的回測結果
但是,這樣的回測結果,究竟能不能在未來「重現」基本上是非常有疑慮的
舉一個例子
假設我們有一個簡單的均線策略,當均線黃金交叉買入,死亡交叉賣出,
在這個策略中,我們會有兩個參數,分別是兩條均線的參數,分別叫做 n1 和 n2
假如我們現在要來最佳化,以下有兩種方法,你會選哪個呢?
第一種最佳化方法:
- n1 從 10 ~ 100
- n2 從 10 ~ 100
分別枚舉(暴力列舉)n1 跟 n2 在上述範圍內的所有可能,並且找最佳化後的結果
第二種最佳化方法
跟上面雷同,但是 n1 跟 n2 只能從以下的數字枚舉
- n1 從 [2, 5, 13, 21, 34, 55, 89]
- n2 從 [2, 5, 13, 21, 34, 55, 89]
選好了嗎?以下開始解說
假如你想找到最佳的報酬率,當然會選第一種方案呀!
畢竟枚舉的數量多了,自然會找到更好的最佳解!
而且現在電腦運算這麼快,第一種方法跟第二種方法,
實際上都只需要幾秒鐘而已,
只是多幾秒鐘,績效變高20%多好呀!
但方案一真的那麼好嗎?
事實是,使用第一種方法,找到過擬合(overfitting)的模型機率也非常高!
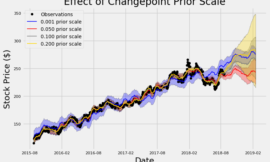
你可以想像下面這三張圖,圖中每一個點,都代表著價格,
一個能預測價格的模型,應該像中間這張圖,
也就是模型跟價格實際的曲線非常接近,
但假如我們求好心切,用各種方式,為模型增加各種變數,暴力枚舉,
最後有可能會變成右邊那張圖片,連歷史的雜訊都給預測了,
最後實際使用的時候,反而效果大打折扣。
 1")
為了避免產生 overfitting 的結果,
我們在做參數最佳化時,就必需要非常小心,並且不要做過多優化
什麼叫做「過多優化」?要怎麼樣才能避免呢?
我們將用更客觀的角度,量化上述兩個最佳化的實驗,哪一個比較好!
我們延續上一篇文章中的介紹,使用「the probability backtest overfitting」
來分析,我們這兩種優化過程中 overfitting 的機率。
下方的實驗結果,都會是兩張圖左右並排,同樣是簡單的均線策略
左邊是「最佳化方法一」,右邊是「最佳化方法二」
首先,我們先做出均線策略,在不同參數下的色溫圖如下,
我們可以發現,枚舉的「密度」上有很大的差異
 2")
由於「最佳化方法一」用了很多的參數,自然會得到比較連續的函數,
然而「最佳化方法二」的參數都比較不連續,代表這樣比較不好嗎?
所以究竟哪種方法好?
所以我們可以利用上一篇文章介紹的「the probability of backtest overfitting」
來幫我們比較這兩種方法的差異:
 3")
上圖中,是overfitting的機率分佈圖,
左邊是「最佳化方法一」,右邊是「最佳化方法二」
我們是使用 sharpe ratio 來當作最後的績效指標,
採樣時,會從「樣本內」的最佳參數,測試在「樣本外」是否也一樣好,
該最佳參數在「樣本內」是第一名,而在樣本外,至少要是「前50%」
我們才會說這樣的優化是有效果的(雖然還是滿寬鬆的XD)
上圖中,大於 0 的樣本,就是優化後有效果的,
而小於 0 的樣本,代表優化並沒有效果。
上圖左圖,分佈偏左側(小於零),代表 overfitting 的機率比較大
而右邊的圖中,分佈比較偏向右邊(x > 0),代表其 overfitting 的機率比較小
第一階段:右邊的「最佳方法二」勝利
實際的原理,可以參考上一篇文章「the probability of backtest overfitting」來獲得更詳細的介紹喔!
除了以上的機率,該文章作者也提供不同的角度,檢視overfitting的問題,
像是
Perfornace degradation
在「樣本內」最好的測略,其績效會在「樣本外」衰減,
以下就是「樣本內的績效跟樣本外的績效」比較圖
左邊是「最佳化方法一」,右邊是「最佳化方法二」
X軸是「樣本內」績效,而Y軸是樣本外績效,
績效以 sharpe ratio 當代表,可以換成 return、maximum drawdown 等等也可以:
 4")
上面兩張圖,將「樣本內」最佳數值,跟「樣本外」的數值做比較,
你會以為「樣本內」績效,應該要跟「樣本外」績效成「正相關」
但現實是,大多數最佳化,都會出現這樣的「負相關 」,稱為 Performance degradation
簡而言之,你會發現
「樣本內」sharpe ratio 越高,則「樣本外」sharpe ratio 越低
代表我們找到的績效越好,越可能是 overfitting 的結果!
是一件非常可怕的事情!
要怎麼比較上述兩張圖的好壞呢?
以視覺上來說,可以看哪張圖的 y 軸數值平均來說比較大,
以統計上來說,可以用線性回歸比較斜率(越負相關越不好)
左邊的回歸後,斜率是 -1.034
而右邊是 -0.988
第二階段:右邊的「最佳方法二」勝利
稍微好一點而已
感覺沒有差很多,有沒有更好的判斷法?
另外我們可以用 Stochastic dominance 來判別「究竟要不要使用最佳化後的結果」
Stochastic dominance 可以想像是學校的兩個班級,A 班跟 B 班
因為 A 班是資優般的關係,所以針對一次模擬考,60分以上的人比 B 班多,是很正常的
假如我們發現 A 班 10 分、20分、30分、…90分以上的人數都比 B 班相同分數以上的人多,
則我們就說 A 班的成績是「隨機優勢」於 B 班的
(A has first-level stochastic domoinance over B)
(好難翻譯呀!)
這邊的 A 跟 B,所指的就是「優化前」跟「優化後」的比較,
下圖中,左邊是「最佳化方法一」,右邊是「最佳化方法二」,其中的
- optimized-IS 就是指用了「樣本內」優化後的策略,的累積分佈圖
- non-optimize-OOS 是指沒有優化過,隨機採樣的分佈圖
其中 x 軸是績效,也就是 sharpe ratio
而 y 軸是累積的樣本數量
假如累積的比較比較慢,代表整體績效比較好,因為分數較高的樣本都在後面,
 5")
我們可以看到,上圖右圖中,優化過的策略,累積的比較慢,所以代表「最佳化方法二」是有效果的,也代表我們用優化後的策略,從統計的角度來說「優化成功的期望值是偏正的」
所以第三階段:右邊的「最佳方法二」再次勝利
你可以從colab上直接運行實驗結果
待改進之處
當然任何研究都會有優缺點的,此篇文章的作者提及一些待改進的空間,
- 就算是有 overfitting 的狀況,當中還是可能會有針對「樣本外」效果很好的策略,舉一個例子,上述的兩種最佳化方法,其實非常巧合的,都優化在(13、21)這個參數位置,也就是說,這兩種方法最後的策略效果一樣,但是過程是不一樣。不過換一種商品,相信也會有不同的特性,究竟整體對策略研發而言,可以進步多少,還有待後續的驗證
- 此方法並沒有考慮參數與模型之間的關係,所以無法將考慮高原參數給考量進去,或許可以藉由機器學習將參數做 clustering 並且以「多參數組」來取代單一「樣本內」最佳參數,來判定過擬合的機率。
- 假如長時間使用,理論上,這個方法會變成越來越無效!因為使用了這種「避免overfitting的方法」,最終你有可能讓你不小心 overfit 這種「避免 overfitting 的方法」(overfit the algorithm that prevent overfitting)。我想這應該是所有這類演算法的通病吧!
overfitting 真的是魔王中的魔王,創造夢境中的夢境!
夢裡中樂透,醒來發現一場夢,又中樂透,醒來又發現一場夢!







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}