現今在股市裡有三大分析方法,即:技術面、基本面、籌碼面等,而各流派似乎也都有自己能自圓其說的選股策略。這三種方法並無法直接說出孰好孰壞,分析方法的選擇跟操作者的心態、個性、紀律都有很大的關係。而我個人覺得買股票除了要買得好(投報率高)以外,賣得快(IRR高)也是很重要的,畢竟投報率會因為時間的流逝而漸漸下降。
因為重視時間對股價影響的我,日K線裡藏有的奧妙便是我想一探究竟的。K線型態學主要就是在探討每根K棒的開盤價、收盤價、最高價、最低價、以及成交量這五大要素所反映出多空雙方的心理交戰。日本著名的投資大師本間宗久影響後人而產生一系列「酒田戰法」的相關書籍裡頭便對K線型態學有了不少篇幅的評析。但人心是會變的,K線型態也是。有沒有方法能幫助我們解讀每天數百張詭譎多變的K線圖呢?

長短期記憶 (Long Short-Term Memory, LSTM) 神經網路
長短期記憶 (LSTM) 神經網路屬於循環神經網路 (RNN) 的一種,特別適合處理和預測與時間序列相關的重要事件。以下面的句子做為一個上下文推測的例子:
“我從小在法國長大,我會說一口流利的??”
由於同一句話裡前面提及到法國這個國家,且後面提到說這個動作。因此,LSTM便能從法國以及說這兩個長短期的記憶中重要的訊號推測出可能性較大的法文這個結果。
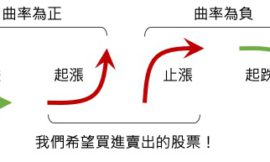
K線圖也述說著類似的事情,股價是隨著時間的流動及重要訊號的出現而做出反應的:
- 在價穩量縮的盤整區間中突然出現一帶量突破的大紅K,表示股價可能要上漲了
- 在跳空缺口後出現島狀反轉,表示股價可能要下跌了
- 在連漲幾天的走勢突然出現帶有長上下影線的十字線,表示股價有反轉的可能
LSTM 要做的事情就是找出一段時間區間的K棒當中有沒有重要訊號(如帶量紅K)並學習之後股價的走勢。
LSTM 實作股價預測
資料是以鴻海(2317)從2013年初到2017年底每天的開盤價、收盤價、最高價、最低價、以及成交量等數據,如果你對這筆資料有興趣請參考附註的方式索取。

首先將資料讀入並存至pandas的DataFrame,另外對可能有N/A的row進行剔除:
資料讀入
import pandas as pd
foxconndf= pd.read_csv('./foxconn_2013-2017.csv', index_col=0 )
foxconndf.dropna(how='any',inplace=True)為了避免原始數據太大或是太小沒有統一的範圍而導致 LSTM 在訓練時難以收斂,我們以一個最小最大零一正規化方法對數據做正規化:
資料正規化
from sklearn import preprocessing
def normalize(df):
newdf= df.copy()
min_max_scaler = preprocessing.MinMaxScaler()
newdf['open'] = min_max_scaler.fit_transform(df.open.values.reshape(-1,1))
newdf['low'] = min_max_scaler.fit_transform(df.low.values.reshape(-1,1))
newdf['high'] = min_max_scaler.fit_transform(df.high.values.reshape(-1,1))
newdf['volume'] = min_max_scaler.fit_transform(df.volume.values.reshape(-1,1))
newdf['close'] = min_max_scaler.fit_transform(df.close.values.reshape(-1,1))
return newdf
foxconndf_norm= normalize(foxconndf)
然後對資料進行訓練集與測試集的切割,另外也定義每一筆資料要有多長的時間框架:
資料編輯
import numpy as np
def data_helper(df, time_frame):
# 資料維度: 開盤價、收盤價、最高價、最低價、成交量, 5維
number_features = len(df.columns)
# 將dataframe 轉成 numpy array
datavalue = df.as_matrix()
result = []
# 若想要觀察的 time_frame 為20天, 需要多加一天做為驗證答案
for index in range( len(datavalue) - (time_frame+1) ): # 從 datavalue 的第0個跑到倒數第 time_frame+1 個
result.append(datavalue[index: index + (time_frame+1) ]) # 逐筆取出 time_frame+1 個K棒數值做為一筆 instance
result = np.array(result)
number_train = round(0.9 * result.shape[0]) # 取 result 的前90% instance做為訓練資料
x_train = result[:int(number_train), :-1] # 訓練資料中, 只取每一個 time_frame 中除了最後一筆的所有資料做為feature
y_train = result[:int(number_train), -1][:,-1] # 訓練資料中, 取每一個 time_frame 中最後一筆資料的最後一個數值(收盤價)做為答案
# 測試資料
x_test = result[int(number_train):, :-1]
y_test = result[int(number_train):, -1][:,-1]
# 將資料組成變好看一點
x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], number_features))
x_test = np.reshape(x_test, (x_test.shape[0], x_test.shape[1], number_features))
return [x_train, y_train, x_test, y_test]
# 以20天為一區間進行股價預測
X_train, y_train, X_test, y_test = data_helper(foxconndf_norm, 20)我們以 Keras 框架做為 LSTM 的實作選擇,首先在面前加了兩層 256個神經元的 LSTM layer,並都加上了Dropout層來防止資料過度擬合(overfitting)。最後再加上兩層有不同數目神經元的全連結層來得到只有1維數值的輸出結果,也就是預測股價:
Keras 模型建立
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.layers.recurrent import LSTM
import keras
def build_model(input_length, input_dim):
d = 0.3
model = Sequential()
model.add(LSTM(256, input_shape=(input_length, input_dim), return_sequences=True))
model.add(Dropout(d))
model.add(LSTM(256, input_shape=(input_length, input_dim), return_sequences=False))
model.add(Dropout(d))
model.add(Dense(16,kernel_initializer="uniform",activation='relu'))
model.add(Dense(1,kernel_initializer="uniform",activation='linear'))
model.compile(loss='mse',optimizer='adam', metrics=['accuracy'])
return model
# 20天、5維
model = build_model( 20, 5 )建立好 LSTM 模型後,我們就用前面編輯好的訓練資料集開始進行模型的訓練:LSTM 模型訓練
# 一個batch有128個instance,總共跑50個迭代
model.fit( X_train, y_train, batch_size=128, epochs=50, validation_split=0.1, verbose=1)
在經過一段時間的訓練過程後,我們便能得到 LSTM 模型(model)。接著再用這個模型對測試資料進行預測,以及將預測出來的數值(pred)與正確答案(y_test)還原回原始股價的大小區間:
LSTM 模型預測股價及還原數值
def denormalize(df, norm_value):
original_value = df['close'].values.reshape(-1,1)
norm_value = norm_value.reshape(-1,1)
min_max_scaler = preprocessing.MinMaxScaler()
min_max_scaler.fit_transform(original_value)
denorm_value = min_max_scaler.inverse_transform(norm_value)
return denorm_value
# 用訓練好的 LSTM 模型對測試資料集進行預測
pred = model.predict(X_test)
# 將預測值與正確答案還原回原來的區間值
denorm_pred = denormalize(foxconndf, pred)
denorm_ytest = denormalize(foxconndf, y_test)LSTM 預測股價結果
讓我們把還原後的數值與答案畫出來,看看效果如何:
LSTM 預測股價結果
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(denorm_pred,color='red', label='Prediction')
plt.plot(denorm_ytest,color='blue', label='Answer')
plt.legend(loc='best')
plt.show()如下圖,藍線是正確答案、紅線是預測股價。雖然整體看起來預測股價與正確答案有類似的走勢,但仔細一看預測股價都比正確答案落後了幾天。如果真的將這個模型應用在買賣策略上我們應該很快就畢業了。

所以我們試著來調整一些設定:
- 時間框架長度的調整
- Keras 模型裡全連結層的 activation 與 optimizaer 的調整
- Keras 模型用不同的神經網路(種類、順序、數量)來組合
- batch_size 的調整、epochs 的調整
- …
經過我們對上述的幾個參數稍微調整過後,我們就得到一個更貼近正確答案的預測結果囉。如果你發現哪些設置能得到更好的結果歡迎你在下面留言跟大家分享。

參考資料
- 詳細的python教學:利用Machine-Learning-選股新手教學
- Keras 說明文件:Keras Documentation
- 另一種 RNN:GRU, Gated Recurrent Unit
- Kaggle 相關競賽:New York Stock Exchange
附註:現在就開始AI選股,免費取得訓練資料
取得訓練資料的方法很簡單,幫冷清的寒舍小小宣傳一下:
- 按右下角分享這篇文章到你的FB
- 將分享截圖傳到 [email protected]
- 一兩天內即可獲得原始資料喔!
熟悉Python與Machine learning,對量化交易有興趣,想挑戰用Machine learning找出股價漲跌的節奏。
AI科學家








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}