我們已經知道怎麼抓取任意一檔股票歷史價格了,但有時候我們一次需要很多檔股票,怎麼辦呢?難道每個股票我們都要寫這麼多行,才能抓下來嗎?今天我們教你如何將上一次的功能包裝成 function,然後一次下載全球指數!
:全球指數一次抓 1")
上次的程式碼爬取台積電
首先,我們上次已經教了怎麼樣爬取一檔股票:「台積電2330」,這次我們重新複習一下,下方的程式,假如有任何一個部分忘記了,都可以去前一個單元複習喔!
import yfinance as yf
df = yf.Ticker("2330.TW").history(period="max")
df:全球指數一次抓 2")
但是以上的程式碼只能爬「台積電」的股價,我想要爬其他的指數怎麼辦呢?
將上述程式碼打包成function
我們可以用function將上面的程式碼打包起來,方便我們多次使用,變成下面這樣,其實跟之前長的非常像,可以先比較一下:首先,第一行多了def crawl_price(stock_id):,這行的意思就是宣告一個可呼叫的程式區塊,叫做crawl_price(stock_id),再來,原本的程式碼前方都被加了4個空白格,代表這些功能是同一個function中被執行的代碼。
import yfinance as yf
def crawl_price(stock_id):
df = yf.Ticker(stock_id).history(period="max")
return df
上面的代碼中,有個特別可以注意的變數:stock_id,當今天stock_id被傳進function中的時候,url就會隨著stock_id的不同,而出現不同的url所以我們就可以爬到不同的股票歷史股價!
既然我們已經寫好了此function,接下來就可以呼叫它,得到不同股票的歷史股價
使用function
假如以後我們需要爬取不同的股票,例如「鴻海2354」,我們就可以寫:
df = crawl_price("2354.TW")
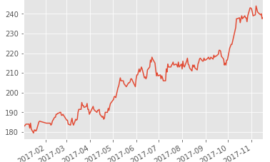
df.Close.plot():全球指數一次抓 3")
接下來我們就來爬取世界上重要的指數吧!
國際重要指數清單
首先我們必須要爬取到國際重要指數清單,可以到以下網址來獲取:
https://finance.yahoo.com/world-indices/
:全球指數一次抓 4")
接下來我們就可以將上述清單給手動複製起來?!
不,我們要用更炫的方法,當然是要用程式來爬呀:
url = "https://finance.yahoo.com/world-indices/"
response = requests.get(url)
import io
f = io.StringIO(response.text)
dfs = pd.read_html(f)
world_index = dfs[0]上述的程式碼,剛開始很簡單,就是用requests.get來獲取此網頁的資料,網頁中的資料都存在response.text中,跟之前一模一樣。
不過第5行有點不一樣,我們使用io.StringIO(response.text)將資料存成檔案f
第6行,我們將此文件利用pd.read_html(f)來分析網頁f中的表格,將所有的表格存成 a list of dataframe
第7行,我們將第一張dataframe給拿出來。
:全球指數一次抓 5")
這樣我們就有了此表格中的symbol和name,以供之後歷史股價的爬取
這個單元的程式碼範例,都可以在colab上直接運行喔!趕快來跑跑看吧!
最後,終於要爬取全球股價了!
萬事俱備!只欠東風,不過由於這次的教學已經很多了,所以大家可以自己練習看看,或是前往下一個單元,來爬取所有的歷史指數吧!
這一系列是我們影音課程的化簡版,
假如對此教程有興趣,歡迎點選下方影音課程,會豐富到炸裂喔~





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}