這篇文章是印度指數預測,2015年發表的就能有191個citation,算是很有名的paper之一,全文特點是只使用了技術指標,來預測大盤每天漲跌,提出了一個有效的優化方式。

這篇paper的作者非常的認真,總共訓練四種不同的模型:Artificial Neural Network (ANN), support vector machine (SVM), random forest (RF) 和 Naive-Bayes (NB)。
這邊假如看不懂沒有關係,可以想像「模型」就是「電腦的大腦」,負責學習每種指標怎麼對應到未來的漲跌。之後有空再來慢慢介紹這些不同的「大腦」背後的數學原理。
此論文主要建構製作兩組traning data:
- 包含十種技術指標
- 為這十種技術指標的看漲看跌
前者為 float (被normalize成-1~1)
而後者為 boolean (也就是只有輸入True和False)。
究竟這些排列組合會迸出什麼樣的火花呢?
選擇模型
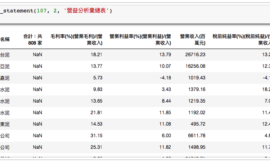
研究發現Random Forest的表現是最好的,而ANN差了一點,
這是滿正常的,畢竟data set還是太小,神經網路很難訓練的非常好。
至於傳統的NB則是最差的。
其實也可以考慮一下LSTM,說不定效果也不錯?
(但因為LSTM還是基於ANN,所以有可能遇到traning set太小的問題)
選擇traning data
如同上面所述,此篇論文總共先用了十種技術指標,以下是這十種常見的指標,為了讓文章不會太冗長,我就不一一解釋了,之後有空再來介紹每種指標的用法。

這篇paper會將這些技術指標的數值,每一項做normalize在-1~1之間,這樣的優化主要是為了ANN和SVM。以下是這個model的架構:

另外,全文的特點是使用了提出了 「Trend Deterministic Data Preparation」,看起來非常的厲害,簡單講就是將這些指標的數值究竟是「看漲」還是「看跌」拿來訓練,而不是訓練指標本身的數值。
例如均線好了,與其拿均線的值來訓練,不如看「股價跟均線的關係」,假如股價在均線之上,就是「看漲」(True),反之則「看跌」(False)。其他指標都能以此類推!
以下就是新增了一層資料的修改的架構:

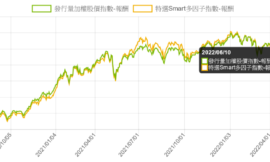
最後發現使用了「Trend Deterministic Data Preparation」
效果好很多!
結論
這篇文章中,可以大概知道每一種model對於技術性指標的數據的效果如何。並且了解了用「Trend Deterministic Data Preparation」來進行優化。經過了非常多參數的比對,發現使用RF model做出來的策略效果最好。然而這只限於頻率為「天」的股價,假如頻率不是「天」,則可能會不一樣~。







{kind=link}
{kind=link}